Polynomial approximation of functions of one variable¶
 |
 |
|
|
## loading python libraries
# necessary to display plots inline:
%matplotlib inline
# load the libraries
import matplotlib.pyplot as plt # 2D plotting library
import numpy as np # package for scientific computing
plt.rcParams["font.family"] ='Comic Sans MS'
from math import * # package for mathematics (pi, arctan, sqrt, factorial ...)
Suppose that a data set $(x_k,y_k)_{k=0..n}$ is given and one wants to model it using a simple function. Since one of the most simple and easy to manipulate set of functions mapping $\mathbb{R}$ into itself is the set of polynomials, one searches for a polynomial $P$ representing the data.
More precisely, there are at least two ways of looking for such a polynomial:
We give below three examples of situations where polynomial approximation can be used.
The world population has been estimated for several years: the following data is available (source http://www.worldometers.info/world-population/world-population-by-year/)
| Year | Pop. |
|---|---|
| 1900 | 1,600,000,000 |
| 1927 | 2,000,000,000 |
| 1955 | 2,772,242,535 |
| 1960 | 3,033,212,527 |
Suppose one wants to
To do so, one can model the evolution of the population versus time as a polynomial and use this polynomial to approximate the answer to these two questions.
Suppose you want to approximate the value of $\pi$. Several methods can be used to do that. One possibility is to write $\pi$ as an integral and then to approximate the function to be integrated by simpler functions such as polynomials, which are easier to integrate.
One formula which expresses $\pi$ as an integral is the following
$$\pi=4\int_{0}^{1}\frac{1}{1+x^2}dx.$$Introducing
$$ d_{atan}: \left\{\begin{array}{l} \mathbb{R} &\rightarrow &\mathbb{R} \\ x &\rightarrow &\frac{1}{1+x^2} \end{array}\right. $$so that
$$\pi=4\int_{0}^{1}d_{atan}(x)dx, $$we want to approximate $d_{atan}$ using polynomials, and then integrate this approximation to obtain an approximation of $\pi$.
Consider a portfolio of assets: think for example of the CAC40 in France (benchmark French stock market index) or of the NASDAC or Dow Jones in USA. In this portfolio, consider a specific asset (i.e. one of the companies in the portfolio).
The return $R_k$ of the asset at day $k$ is a measure of what you gain (or lose) that day if you possess this asset. Similarly, let us denote by $R^m_k$ the market portfolio return on day $k$, which again is a measure of what you gain (or lose) that day if you possess the whole portfolio.
The Capital Asset Pricing Model (CAPM) provides a theoretical relation to estimate returns on a specific asset and on the whole market portfolio through the equation
$$ R_k = \alpha + \beta \, R^m_k. $$The parameter $\beta$ represents the systematic risk (associated to the market): when the market portfolio return moves by 1 the asset's return variation is $\beta$. The higher $\beta$, the more the corresponding asset varies when the market varies, that is, the more risky the asset.
The parameter $\alpha$ represents the risk associated to the asset, that is the return of the asset if the market does not change.
Parameter estimation: Being given the values of $(R^m_k)_{k=1..n}$ and $(R_k)_{k=1..n}$ for $n$ days, one wants to estimate the parameters $\alpha$ and $\beta$ in order to model the behavior of the corresponding asset, understand how risky it is and estimate its future trend.
To do so, one has to approximate the data by a polynomial of degree 1: $R_k = Q(R_k^m)$ where $Q(x)=\alpha + \beta\,x$. The question is to find "good" values $\alpha^*$ and $\beta^*$ for the parameters $\alpha$ and $\beta$ so that the approximated affine model is close to the data.
Once $\alpha^*$ and $\beta^*$ are computed, one also wishes to know how confident one can be when using these values to model the behavior of the asset.

Joseph-Louis Lagrange (1736 - 1813). Joseph-Louis Lagrange is an Italian (who became French by the end of his life) mathematician and astronomer. He made significant contribution in analysis, number theory and both classical and celestial mechanics. He is one of the creators of the calculus of variations, which is a field of mathematical analysis that uses variations, which are small changes in functions and functionals, to find maxima and minima of functionals. He is best known for his contributions to mechanics (initiating a branch now called Lagragian mechanics), presenting the "mechanical principles" as a result of calculus of variations. Concerning calculus, he contributed to discover the importance of Taylor series (sometimes called Taylor-Lagrange series) and published in 1795 an interpolation method based on polynomials now called "Lagrange polynomials". Note that this interpolation method was already suggested in works of Edward Waring in 1779 and was a consequence of a formula published in 1783 by Leonhard Euler.
A polynomial $P$ is said to interpolate the data if $P(x_k)=y_k$ for all $k=0,\ldots,n$. $P$ is then called an interpolation polynomial (associated to the data $(x_k,y_k)_{0\leq k\leq n}$).
In this context, the $x_k$ are called interpolation points, or interpolation nodes. In the sequel, when we talk about interpolation points or nodes, we always assume that they are pairwise disjoint.
is the unique polynomial of degree at most $0$ interpolating the data.
where $Q_2$ is a polynomial of degree at most $2$. The conditions $P_2(x_0)=y_0$, $P_2(x_1)=y_1$ and $P_2(x_2)=y_2$ are satisfied if and only if $Q_2(x_0)=0$, $Q_2(x_1)=0$ and $Q_2(x_2)=y_2-\left(y_0 + (x-x_0)\frac{y_1-y_0}{x_1-x_0}\right)$. The first two conditions are equivalent to having $Q_2$ of the form $Q_2(x)=a(x-x_0)(x-x_1)$ for some constant $a$, which is fixed by the third condition. This proves the existence and uniqueness of an interpolation polynomial of degree at most $2$ for this data.
More generally, one can prove that for any data set of $n+1$ points where the $x_k$ are all different, there exists a unique interpolation polynomial of degree at most $n$.
Let $x_0, x_1, \cdots, x_n$ be a set of $n+1$ different interpolation points, and $y_0,y_1,\cdots,y_n$ be a set of arbitrary real numbers. There exists a unique polynomial $P_n$ of degree at most $n$ such that, $P_n(x_k) = y_k$ for all $0 \leq k \leq n.$ This polynomial is called the Lagrange interpolation polynomial, and is explicitly given by
$$P_n(x) = \sum_{i=0}^n y_i L_i(x),$$where $(L_i)_i$ are the Lagrange basis polynomials given by
$$ L_i(x) = \prod_{j \neq i}\frac{x - x_j}{x_i - x_j}, \quad{} 0 \leq i \leq n.$$The polynomial $P_n$ is often simply called the interpolation polynomial associated to the data.
Proof. By definition of the $L_i$, we have
$$L_i(x_j) = \begin{cases} 0 & \text{if } j \neq i, \\1 & \text{if } j = i.\end{cases}$$The formula proposed for $P_n$ therefore satisfies $P_n(x_j) = y_j$ for all $j=0,\ldots,n$, and $P_n$ is of degree at most $n$, which proves the existence. To prove uniqueness, suppose there exist two polynomials $P_n$ and $Q_n$ solution to the problem. Then, the polynomial $P_n-Q_n$ is of degree at most $n$ and has at least $n+1$ roots ($x_0\ldots x_n$). Thus, $P_n-Q_n$ is the null polynomial and $P_n$ is identical to $Q_n$.
Be mindful that there are two different things called Lagrange polynomial:
$\mathbf{a}=(a_i)_{i=0\ldots n}$ being $n+1$ constants to be found. For $k=0,\ldots,n$, the $n+1$ conditions $P(x_k)=y_k$ then write:
$$ a_0 + a_1 x_k + a_2 x_k^2 + \ldots +a_n x_k^n = y_k\quad{} \text{for} \quad{} k=0,\ldots,n, $$which is a linear system to be solved for $\mathbf{a}$. The problem can be written in a matrix form:
$$ V_n\, \mathbf{a}=\mathbf{y}\quad{} \text{where}\quad{} V_n=\left(\begin{array}{ccccc} 1 & x_0 & x_0^2 & \ldots & x_0^n \\ 1 & x_1 & x_1^2 & \ldots & x_1^n \\ \vdots & & & &\vdots \\ 1 & x_n & x_n^2 & \ldots & x_n^n \end{array}\right). $$The corresponding matrix is the well-known Vandermonde matrix which is invertible, provided the $(x_k)_k$ are distinct. This proves the existence and uniqueness of $\mathbf{a}$ and then of $P_n$.
The previous remark also provides a straightforward method for computing the interpolation polynomial in the monomial basis, that is the coefficients $(a_0,\ldots,a_n)$.
Hints: you can implement the Vandermonde matrix yourself, or look at the numpy.vander function. In order to compute $a$, the function numpy.linalg.solve should be useful.
def interpVDM(x,y):
"""
Computation of the coefficients of the interpolation polynomial in the monomial basis, using a Vandermonde matrix
-----------------------
Inputs:
x : the interpolation nodes (1D array with pairewise distinct entries)
y : the prescribed values at the interpolation nodes (1D array having the same size as x)
Output:
a : the coefficients of the interpolation polynomial in the monomial basis (1D array having the same size as x)
"""
# Construct the Vandermonde matrix
M = np.vander(x, increasing=True)
# Solve the linear system
a = np.linalg.solve(M, y)
return a
# Test cell. We use our code on a simple example, where we know that the output should be P(X) = X^2,
# or equivalently a = [0, 0, 1]
x = np.array([-1, 1, 2])
y = np.array([1, 1, 4])
# There exists a unique polynomial P of degree at most 2 such that P(-1)=1, P(1)=1, and P(2)=4.
# P(X) = X^2 satisifies those assumptions, so it is the solution.
a = interpVDM(x,y)
print('Your code output: ', a)
print('The theoretical solution: ', np.array([0., 0., 1.]))
Your code output: [0. 0. 1.] The theoretical solution: [0. 0. 1.]
Once the coefficients $(a_0, a_1, \ldots, a_n)$ of the interpolation polynomial in the monomial basis have been computed, we would like to evaluate the polynomial $P$, that is, to compute the value of
$$P(X) = a_0 + a_1 X + \ldots a_{n}X^{n},$$for several values of $X$. An efficient way to do that is to use the Horner scheme. The idea is to avoid taking the powers of $X$ by rewriting the polynomial in the following form
$$ P(X)= a_0 + X\,\, \bigg(a_1 \,+\, X\,\, \Big(a_2\, +\, \ldots\, +\,X\,a_{n}\Big) \bigg)\,. $$Consequently, the algorithm to evaluate $P$ is
def evalHorner(a,X):
"""
Evaluation of a polynomial using Horner's scheme.
-----------------------
Inputs:
a : the coefficients of the polynomial P in the monomial basis
X : an array of values at which we want to evaluate P
Output:
an array containing the values P(x) for each x in X
"""
PX = a[-1]
for k in np.arange(1,a.size):
PX = a[-1-k] + X*PX
return PX
# Test cell. We use our code on a simple example
a = np.array([0, -1, 2])
# We consider the polynomial P(X) = -X + 2*X^2
X = np.array([-1, 0, 1, 2])
PX = evalHorner(a,X)
# We evaluate P at the values stored in X
print('Your code output: ', PX)
print('The theoretical solution: ', -X + 2*X**2)
Your code output: [3 0 1 6] The theoretical solution: [3 0 1 6]
We can now test the Lagrange interpolation for different datasets $(x_k,y_k)$.
Check that the interpolation polynomial indeed interpolates the data (i.e. that the graph of the polynomial goes trough ALL the data points).
In this cell, the vectors x and y are the vectors containing the data: $x[k]=x_k$ and $y[k]=y_k$. Using these data, you can compute the coefficients a of the corresponding interpolation polynomial. Then, to plot this polynomial on a given interval $I$ (here $I=[0,1]$), it remains to discretize $I$ in a vector X and to compute the values of the polynomial at these points.
Important: Here and in the sequel, be careful not to confuse the small x, which contains the interpolation nodes, and the capital X, which contains the values at which we evaluate the polynomial in order to plot it!
n = 10 # number of interpolation points (minus 1)
x = np.linspace(0,1,n+1) # n+1 equispaced nodes (x_k) in [0,1]
y = np.random.rand(n+1) # n+1 random values for (y_k), uniform in [0,1] (you can try other distributions if you want to)
X = np.linspace(0, 1, 1001) # values in [0,1] where the interpolation polynomial has to be computed
# computes the coefficients of the polynomial and its values at point X
a = interpVDM(x,y)
PX = evalHorner(a,X)
# plot
plt.figure(figsize = (15,7))
plt.plot(X,PX,label="Interpolation Polynomial")
plt.plot(x,y,marker='o',linestyle='',label="dataset")
plt.legend(fontsize = 15)
plt.show()

In the previous section, we assumed that we were given a dataset $(x_k,y_k)_{k=0,\ldots,n}$, an presented a way to compute the interpolation polynomial of degree at most $n$ for this dataset.
In this section, we assume that we are given a continuous function $f$ on an interval $[a,b]$, and that we want to approximate this function by a polynomial of degree at most $n$. Interpolation naturally gives use a way to do that, by considering the interpolation polynomial for a dataset of the form $(x_k,f(x_k))_{k=0,\ldots,n}$.
Let $f$ be a continuous function on an interval $[a,b]$, and $x_0,x_1,\ldots,x_n$ be $n+1$ different points belonging to $[a,b]$. The interpolation polynomial of $f$, denoted $P_n(f)$, is the unique polynomial of degree at most $n$ such that
$$ P_n(f)(x_k) = f(x_k) \qquad{} \text{for all }k=0,\ldots,n. $$Notice that the interpolation polynomial depends on the choice of the nodes $x_k$.
The local interpolation error, denoted $e_n(f)(x)$, is defined as
$$ e_n(f)(x) = \vert f(x) - P_n(f)(x) \vert. $$The global interpolation error, denoted $E_n(f)$, is defined as
$$ E_n(f) = \sup_{x\in[a,b]} e_n(f)(x) = \sup_{x\in[a,b]} \vert f(x) - P_n(f)(x) \vert. $$The question is to know whether $P_n(f)$ is a good approximation of $f$. More precisely one has to answer the following questions:
We first consider equidistant nodes in $[-1,1]$, that is,
$$ x_k = -1 + \frac{2k}{n}, \quad{} 0\leq k \leq n, $$and numerically investigate the behavior of the interpolation polynomial $P_n(f)$ and the error $e_n$, for the following functions
$$ f_1(x) = \vert x \vert, \qquad{} f_2(x) = \sin(2\pi x), \qquad{} f_3(x) = e^{2x}\sin\left(10x\right). $$## definition of the functions f1, f2 and f3
def f1(x):
return np.abs(x)
def f2(x):
return np.sin(2*np.pi*x)
def f3(x):
return np.exp(2*x)*np.sin(10*x)
def compare_Pnf_f(f, x, X):
"""
Plots f and P_n(f) one one side, and the local error e_n(f) = |f-P_n(f)| on the other side
-----------------------
Inputs:
f : continuous function on [-1,1]
x : 1D array containing the interpolation nodes in [-1,1]
X : 1D array containing the points at which f and P_n(f) will be plotted
Output: 2 figures
left : f and P_n(f)
right : the local error e_n(f)
"""
y = f(x) # values of f at the nodes
a = interpVDM(x, y) # the coefficients of the interpolation polynomial P_n(f)
PnfX = evalHorner(a, X) # values of P_n(f) at the points stored in X
n = x.size - 1 # number of nodes, to be dispayed in the title of the figures
plt.figure(figsize=(20, 8))
plt.subplot(121)
plt.plot(X, f(X), label = 'Target function $f$')
plt.plot(x, f(x), marker='o', linestyle='', label = 'data set')
plt.plot(X, PnfX, '--',label = 'Interpolation polynomial $P_n(f)$')
plt.legend(fontsize = 18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize=18)
plt.title('f and its interpolation polynomial, n= %i' %n, fontsize = 18)
plt.subplot(122)
plt.plot(X, abs(f(X) - PnfX), label = '$e_n(f) = |f-P_n(f)|$')
plt.plot(x, 1e-16*np.ones(x.size), marker='o', linestyle='', label = 'Interpolation nodes')
plt.legend(fontsize = 18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize=18)
plt.yscale('log')
plt.title('Local interpolation error e_n(f) in log-scale, n= %i' %n, fontsize = 18)
plt.show()
Read and try to understand the code of the function compare_Pnf_f in the previous cell. Run the following cell for different values of $n$ and different functions ($f_1$, $f_2$ and $f_3$). Comment upon the obtained results.
n = 500 # degree of the interpolation polynomial
x = np.linspace(-1,1,n+1) # n+1 equispaced nodes for the interpolation
X = np.linspace(-1,1,5001) # the points at which f, P_n(f) and e_n(f) will be plotted
compare_Pnf_f(f2, x, X)

When $n$ grows, the interpolation polynomial $P_n(f)$ seems to be converging to $f$ for the functions $f_2$ and $f_3$, but not for $f_1$.
In order to better understand what we just observed, we now try to estimate the distance between $P_n(f)$ and $f$. Given $n+1$ interpolations nodes $x_0,\ldots,x_n$, it will be convenient to introduce the polynomial $\Pi_{x_0,\ldots,x_n}$ of degree $n+1$ as
$$ \Pi_{x_0,\ldots,x_n}(x) = (x-x_0)(x-x_1)\cdots(x-x_n). $$Let $f : [a,b] \to \mathbb{R}$ be $n+1$ times differentiable and consider $n+1$ distinct interpolations nodes $x_0,\ldots,x_n$ in $[a,b]$. Then, for every $x$ in $[a,b]$, there exists $\xi_x \in [a,b]$ such that
$$ f(x) - P_n(f)(x) = \frac{\Pi_{x_0,\ldots,x_n}(x)}{(n+1)!} f^{(n+1)}(\xi_x). $$In particular, we get that
$$ E_n(f) = \sup_{x\in[a,b]} \vert f(x) - P_n(f)(x) \vert \leq \frac{\sup_{x\in [a,b]} \left\vert \Pi_{x_0,\ldots,x_n}(x) \right\vert }{(n+1)!} \sup_{x\in [a,b]} \left\vert f^{(n+1)}(x) \right\vert. $$Proof. [$\star$] If $x$ is equal to one of the nodes $x_k$, the first equality holds. So let us prove it if $x\neq x_k$ for all $k=0\ldots n.$
To do so, let $x$ be given and consider $P_{n+1}(f)$, the interpolation polynomial of $f$ of degree at most $n+1$ for the $n+2$ nodes $(x,x_0,x_1,\ldots ,x_n)$.
Since $P_{n+1}(f)$ interpolates $f$ at point $x$, we have:
$$f(x)-P_n(f)(x) = P_{n+1}(f)(x)-P_n(f)(x).$$Then, notice that the $n+1$ points $(x_0,\ldots,x_n)$ are roots of the polynomial $P_{n+1}(f)-P_n(f)$, of degree at most $n+1$. As a consequence, we know that there exists a constant $C$ such that, for all $t\in\mathbb{R}$,
\begin{align} P_{n+1}(f)(t) - P_n(f)(t) &= C \, (t - x_0)(t - x_1) \cdots (t - x_n) \\ &= C \, \Pi_{x_0, \ldots, x_n}(t). \end{align}In particular, for $t=x$ we get:
$$f(x)-P_n(f)(x) = P_{n+1}(f)(x)-P_n(f)(x) = C\, \Pi_{x_0,\ldots,x_n}(x).$$It remains to compute the constant $C$. To do so, let us consider the function
$$g(t) = P_{n+1}(f)(t) - f(t).$$This function has at least $n+2$ distinct zeros $x$, $x_0$, ... $x_n$ in $[a,b]$, therefore we can apply $n+1$ times Rolle's theorem to get that $g'$ has at least $n+1$ distinct zeros in $[a,b]$. Repeating this argument recursively until we reach $g^{(n+1)}$, we get that $g^{(n+1)}$ has at least one zero in $[a,b]$:
$$\exists \xi_x \in[a,b], \quad{} g^{(n+1)}(\xi_x)=0.$$Using the fact that $P_{n+1}(f)(t)=P_n(f)(t) +C \, \Pi_{x_0,\ldots,x_n}(t)$ together with the fact that the degree of $P_n(f)$ is at most $n$, we obtain
\begin{align}0 &= g^{(n+1)}(\xi_x) \\& = P_{n+1}(f)^{(n+1)}(\xi_x) - f^{(n+1)}(\xi_x) \\& = C\,(n+1)! - f^{(n+1)}(\xi_x),\end{align}and finally
$$C = \frac{f^{(n+1)}(\xi_x)}{(n+1)!}$$which ends the proof of the first equality. The estimates for $E_n(f)$ immediately follows.
From the previous theorem we get an estimation for the interpolation error which depends on
This suggests that the choice of the the nodes could have a significant impact on the quality of the approximation. We are going to investigate this point in the next subsection.
Before that, notice that the above theorem allows us to conclude that $P_n(f)$ converges to $f$ for some very regular functions.
Let $f : [a,b] \to \mathbb{R}$ be $\mathcal{C}^\infty$ and such that
$$ \exists M>0, \quad{} \forall n\geq 0,\quad{} \sup_{x\in [a,b]} \lvert f^{(n)}(x)\rvert \leq M^n. $$Then, whatever the choice of the interpolation nodes, $P_n(f)$ converges uniformly to $f$ on the interval $[a,b]$:
$$ E_n(f) = \sup_{x\in[a,b]}\,\lvert f(x) - P_n(f)(x) \rvert \underset{n\to\infty}{\longrightarrow}0. $$Proof. Starting from the result of previous theorem on the estimation of the error, and using that, for each $x\in[a,b]$ and each interpolation point $x_k$, $\vert x-x_k\vert \leq b-a$, we get
$$\lvert f(x) - P_n(f)(x) \rvert \leq \frac{\sup_{x\in [a,b]}\lvert \Pi_{x_0,\ldots,x_n}(x) \rvert}{(n+1)!} M^{n+1} \leq \frac{\left(M(b-a)\right)^{n+1}}{(n+1)!}$$which goes to zero when $n$ goes to infinity.
This theorem applies to the functions $f_2(x) = \sin(2\pi x)$ and $f_3(x) = e^{2x}\sin\left(10x\right)$ that we already considered before (for $f_3$ it is not completely obvious, but you can try to show it as an exercise), and proves that, in theory, $P_n(f)$ should converge to $f$ in both cases.
Complete the following function ErrorEqui to compute the global interpolation error $E_n(f)$ for equidistant interpolation points and several values of $n$. In practice, you can approximate
by
$$ \max_{i\in I}\,\lvert f(X_i) - P_n(f)(X_i) \rvert, $$where $\left(X_i\right)_{i\in I}$ is a sufficiently fine discretization of $[a,b]$.
Then, use this function in the subsequent cell to plot the evolution of $E_n(f)$ with $n$ (use a log scale), for both functions $f_2$ and $f_3$. What happens when $n$ becomes too large? Comment on the results.
def ErrorEqui(f, nmax, X):
"""
Approximates the global interpolation error E_n(f) = sup_{[-1,1]} |f-P_n(f)| for n=0,...,nmax,
by computing sup_{X_i in X} |f(X_i)-P_n(f)(X_i)|.
Here P_n(f) is the interpolation polynomial for equidistant nodes.
-----------------------
Inputs:
f : continuous function on [-1,1]
nmax : integer, largest n for which the error has to be computed
X : 1D array containing the points at which f and P_n(f) will be evaluated to compute E_n(f)
Output:
tab_Enf : 1D array containing [E_0(f), E_1(f), ..., E_{nmax}(f)]
"""
tab_n = np.arange(0,nmax+1) # values of n for which the error E_n(f) = sup |f-P_n(f)| has to be computed
tab_Enf = np.zeros(nmax+1) # Pre-allocation
for n in tab_n:
x = np.linspace(-1,1,n+1) # n+1 equispaced nodes to compute the interpolant
y = f(x) # values of f at the nodes
a = interpVDM(x, y) # the coefficients of the interpolation polynomial P_n(f)
PnfX = evalHorner(a, X) # values of P_n(f) at the points stored in X
tab_Enf[n] = np.max(np.abs( PnfX - f(X) )) # computation of E_n(f)
return tab_Enf
## graphical study of the convergence
nmax = 25
X = np.linspace(-1,1,1001)
tab_Enf2 = ErrorEqui(f2, nmax, X)
tab_Enf3 = ErrorEqui(f3, nmax, X)
tab_n = np.arange(0,nmax+1)
plt.figure(figsize=(10, 6))
plt.plot(tab_n, tab_Enf2, marker='o', label='$f_2$')
plt.plot(tab_n, tab_Enf3, marker='o', label='$f_3$')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for equidistant nodes, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()

At first (say for $nmax=25$), the error seems to go to zero, as predicted by the theory. However, if we keep increasing $n$ (say $nmax=50$), we see that the error saturates and stops decreasing. This is due to the rounding errors, and to our choice of algorithm to compute the interpolation polynomial.
On this example, we again see clearly the two different sources of errors that occur when we try to approximate $f$.
The error between $f$ and $P_n(f)$ are predominant when $n$ is small, but when $n$ becomes larger the rounding error start to have a noticeable impact.

Carl David Tolmé Runge (1856-1927). Carl David Tolmé Runge was a German mathematician, physicist, and spectroscopist. In the field of numerical analysis, he is the co-developper of the Runge-Kutta method to approximate the solution to differential equations. He discorvered the now called "Runge's phenomenon" in 1901 when exploring the behavior of errors when using polynomial interpolation to approximate certain functions. Runge's phenomenon is a problem of oscillation at the edges of an interval that occurs when using polynomial interpolation with polynomials of high degree over a set of equispaced interpolation points. The discovery was important because it shows that, for equispaced points, going to higher degrees does not always improve accuracy. The phenomenon is similar to the Gibbs phenomenon in Fourier series approximations.
In the previous subsection, we studied two examples of $\mathcal{C}^\infty$ functions for which, with equidistant interpolation nodes, the interpolation polynomial $P_n(f)$ was converging uniformly to $f$ on a given interval. However, even for $\mathcal{C}^\infty$ functions, the theoretical results we have only guarantee the convergence under some additional assumption on the behavior of the derivatives of $f$. The following example
$$f_{Runge} (x) = \frac{1}{1+25x^2},$$due to Runge, shows that there exist $\mathcal{C}^\infty$ functions, which are rather innocent-looking, for which $P_n(f)$ does not converge uniformly to $f$ with equidistant nodes.
Complete the following cell in order to plot the interpolation polynomial of the Runge function on $[-1,1]$ for $n=10$ and $n=20$ equidistant nodes. You can use the compare_Pnf_f function. What do you observe? You can confirm your observations using the ErrorEqui function.
def f_Runge(x):
return 1/(1+25*x**2)
n1 = 10
n2 = 20
x1 = np.linspace(-1, 1, n1+1) # n1+1 equispaced nodes in [-1,1]
x2 = np.linspace(-1, 1, n2+1) # n2+1 equispaced nodes in [-1,1]
X = np.linspace(-1, 1, 1001) # the points at which f, P_n(f) and e_n(f) will be evaluated and plotted
# Plots of f, P_n(f) and e_n(f)
compare_Pnf_f(f_Runge, x1, X)
compare_Pnf_f(f_Runge, x2, X)
## graphical study of the convergence
nmax = 25
X = np.linspace(-1,1,1001)
tab_Enf_Runge = ErrorEqui(f_Runge, nmax, X)
tab_n = np.arange(0, nmax+1)
plt.figure(figsize=(10, 6))
plt.plot(tab_n, tab_Enf_Runge, marker='o', label='$f_{Runge}$')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for equidistant nodes, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()



We see that, for this example and with equidistant nodes, $P_n(f)$ does not converge uniformly to $f$, as there are oscillations close to the boundary of the interval, whose amplitude grow with $n$. The plot of $E_n(f)$ confirms that $E_n(f)$ does seem to diverge.
One can thus infer that, for this function $f_{Runge}$ and equidistant nodes, the successive derivatives of $f_{Runge}$ increase too quickly with respect to the term $\Pi_{\bar x_0,\ldots,\bar x_n}(x)/(n+1)!$ in the error approximation.
This example strongly suggests that polynomial interpolation with a large number of nodes is not necessarily a good strategy to approximate functions, if we use equidistant nodes. As we will see in the next subsection, polynomial interpolation with a large number of nodes actually performs well for any function which is at least somewhat smooth (say Lipschitz), provided appropriate nodes are selected, like the Chebyshev nodes.

Pafnuty Lvovich Chebyshev (1821-1894). Pafnuty Lvovich Chebyshev is a Russian mathematician. He is known for his work in the fields of probability, statistics, mechanics, and number theory. He is also known for the "Chebyshev polynomials", which are a sequence of orthogonal polynomials. He introduced these polynomials to minimize the problem of Runge's phenomena in polynomial approximation of functions. These polynomials are also used in numerical integration and are solution to special cases of the Sturm–Liouville differential equation that occur very commonly in mathematics, particularly when dealing with linear partial differential equations.
To enhance the quality of the approximation, one can look for better nodes $(x_k)_k$. Indeed, recalling the estimation:
$$ f(x) - P_n(f)(x) = \frac{\Pi_{x_0\ldots\,x_n}(x)}{(n+1)!} f^{(n+1)}(\xi_x), $$one could choose the interpolations nodes $x_0, x_1, \ldots, x_n$ so as to minimize the quantity
$$ \left\Vert \Pi_{x_0\ldots\,x_n} \right\Vert_\infty = \sup_{x\in [a,b]}\lvert \Pi_{x_0\ldots\,x_n}(x) \rvert = \sup_{x\in [a,b]}\lvert (x-x_0)(x-x_1)\ldots(x-x_n) \rvert. $$It turns out that one choice of $n+1$ nodes $x_0,\ldots,x_n$ that achieves this minimum for $[a,b] = [-1,1]$ is well-known, and is related to the Chebyshev polynomials that we now introduce.
The Chebyshev polynomials satisfy the following important properties.
$T_n$ is a polynomial of degree $n$ and, if $n\geq 1$, the leading coefficient is $2^{n-1}$.
For all $\theta \in \mathbb{R}$,
$T_{n+1}(x) = 2^{n}(x-\hat{x}_0)\cdots(x-\hat{x}_{n})$.
For $x\in [-1,1]$, one has $-1 \leq T_n(x) \leq 1$. If we let $\hat{y}_k = \cos\left(\frac{k\pi}{n}\right)$ for $0\leq k \leq n$, we have
$$T_{n+1}(X) = 2XT_{n}(X) - T_{n-1}(X),$$Proof. [$\star$]
- Degree and leading coefficient: By definition, $T_0$ is of degree $0$, and $T_1$ is of degree $1$ and has leading coefficient $2^{1-1} = 1$. Let us show the same result for $n+1>1$ by induction, assuming the result is true for all $k \leq n$. Using
we have that $T_{n+1}$ is the sum of a polynomial of degree $n+1$ and a polynomial of degree $n-1$. Thus, it is of degree $n+1$. Finally, the leading coefficient of $T_{n+1}$ is the leading coefficient of $2XT_{n}(X)$, it is therefore equal to $2\times 2^{n-1} = 2^n$.
\begin{align} T_{n+1}(\cos\theta) &= 2\cos\theta T_{n}(\cos\theta) - T_{n-1}(\cos\theta) \\ &= 2\cos\theta \cos(n\theta) - \cos((n-1)\theta) \\ &= \cos((n+1)\theta) + \cos((n-1)\theta) - \cos((n-1)\theta) \\ &= \cos((n+1)\theta). \end{align}
- Trigonometric identity: We also prove this by induction. For the base cases, we indeed have $T_0(cos\theta) = 1 = \cos(0\theta)$ and $T_1(\cos\theta) = \cos\theta = \cos(1\theta)$. Let us assume the result is true for $k\leq n$, and show that it then holds for $n+1$. Using the assumption for $k=n-1,n$, and the trigonometric formula $2\cos(a)\cos(b) = \cos(a+b) + \cos(a-b)$, we get
$$ T_{n+1}(\hat x_k) = T_{n+1}(\cos\theta_k) = \cos((n+1)\theta_k) = 0. $$
- Roots: We use the fact that $T_{n+1}(\cos\theta)=\cos((n+1)\theta)$, and look for zeros of $\cos((n+1)\theta)$, that is, $(n+1)\theta = \frac{\pi}{2} \text{ mod } \pi$. In particular, setting $\theta_k=\frac{2k+1}{2(n+1)}\pi$, $k=0,\ldots,n$, we have
All the $\hat x_k$ for $k=0,\ldots,n$ are different because all the $\theta_k$ belong to $(0,\pi)$ and the cosine function is injective on that interval. Therefore, we have found $n+1$ zeros of $T_{n+1}$ and since $T_{n+1}$ is a polynomial of degree $n+1$ we have all of them.
$$ T_{n+1}(X) = C \left(X - \hat{x}_0\right) \left(X - \hat{x}_1\right)\cdots \left(X - \hat{x}_{n}\right), $$
- Expression of $T_{n+1}$: Since the $\hat x_k$, $k=0,\ldots,n$, are the roots of $T_{n+1}$ which is of degree $n+1$, we must have
for some constant $C$, which must be $2^{n}$ because we have already proven that the leading coefficient of $T_{n+1}$ is $2^{n}$.
- Extremal values: We again use the formula $T_n(\cos\theta) = \cos(n\theta)$, which immediately yields that $-1 \leq T_n(x) \leq 1$ for $x\in[-1,1]$. In order to find the extremal values, we solve $\cos(n\theta) = \pm 1$, which gives the announced values $\hat y_k$.
It turns out that the roots $\hat x_k$ of $T_{n+1}$ make excellent interpolation nodes, as we will see in a moment.
Consider the interval $[-1,1]$. For any $n\geq 0$, the $n+1$ Chebyshev nodes are the roots of the Chebyshev polynomial $T_{n+1}$, given by
$$ \hat x_k = \cos\left(\frac{2k + 1}{2n+2}\pi\right), \qquad{} 0 \leq k \leq n. \nonumber $$The extremal points $\hat y_k$ make equally excellent interpolation nodes, but to keep things simple we only consider interpolation at the nodes $\hat x_k$ in this course.
For a given value of $n$, let us denote by $(\overline x_k)_{k=0,\ldots,n}$ the $n+1$ equidistant points in $[-1,1]$ and let us compare on $[-1,1]$ the two following polynomials:
$$\bar \Pi(x) = \Pi_{\bar x_0\ldots\,\bar x_n}(x) = (x- \overline x_0)(x-\overline x_1)\cdots(x-\overline x_n),$$$$\hat \Pi(x) = \Pi_{\hat x_0\ldots\,\hat x_n}(x) = \frac{T_{n+1}(x)}{2^{n}} = (x-\hat x_0)(x-\hat x_1)\cdots(x-\hat x_n),$$corresponding to equidistant nodes and to Chebyshev nodes respectively.
Complete the following function to obtain the roots of $T_n$ for any given integer $n$. Notice that your are asked for the roots of $T_n$, and not of $T_{n+1}$, so that calling xhat(n+1) gives you $n+1$ Chebyshev nodes, in the same way that np.linspace(-1,1,n+1) gives $n+1$ equidistant nodes. The roots of $T_n$ are simply given by $\cos\left(\frac{2k + 1}{2n}\pi\right)$ for $0 \leq k \leq n-1$.
def xhat(n):
"""
function returning the zeros of Tn
-----------------------
Inputs:
n : the degree of Tn
Output:
1D array containing the roots of Tn
"""
if n == 0:
return np.array([])
else:
x = np.cos( (2*np.arange(0,n)+1)*np.pi / (2*n) )
return x
Complete the code of the function evalPolywithRoots in the following cell, to evaluate a polynomial of the form:
def evalPolywithRoots(x,X):
"""
Evaluation of a monic polynomial described by its roots.
-----------------------
Inputs:
x : the zeros of polynomial P (P = \prod_k (x-x_k))
X : an array of values at which we want to evaluate P
Output:
an array containing the values P(X_k) for each X_k in X
"""
PX = 1
for xk in x:
PX = PX * (X-xk)
return PX
Complete the following cell to plot $\overline \Pi$ and $\hat \Pi$ on $[-1,1]$ for different values of $n$. What do you observe? How do you expect this to impact the quality of polynomial interpolation using Chebyshev nodes versus equidistant nodes?
n = 10
x_equi = np.linspace(-1,1,n+1) # n+1 equispaced nodes
x_cheb = xhat(n+1) # n+1 chebychev nodes
X = np.linspace(-1, 1, 1001) # the points at which the polynomials will be evaluated and plotted
# Evaluate \bar Pi for equispaced nodes
Pi_equi = evalPolywithRoots(x_equi, X)
# Evaluate \hat Pi for chebychev nodes
Pi_cheb = evalPolywithRoots(x_cheb, X)
# plots
plt.figure(figsize = (20,12))
plt.plot(X, Pi_equi, label='$ \overline{\Pi}$ (equidistant nodes)')
plt.plot(X, Pi_cheb, label='$\hat \Pi$ (Chebyshev nodes)')
plt.xlabel('x',fontsize = 18)
plt.legend(fontsize = 18, loc = 'lower center')
plt.title('n = %i' %n, fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()

We observe that the two polynomials oscillate, but the oscillations have a much larger amplitude at the edges of the interval in the case of equidistant nodes, so that the upper bound for $\lvert\overline \Pi\rvert$ is greater than the one for $\lvert \hat \Pi \rvert$. This suggests that interpolation should behave better if based on Chebyshev nodes rather than on equidistant ones.
In fact, for a given value of $n$, the following theorem proves that the Chebyshev nodes $\hat x_0,\ldots,\hat x_n$ are an optimal choice of nodes to minimize $\|\Pi_{x_0,\ldots,x_n}\|_\infty$:
Proof. [$\star$] Let $x_0,\ldots,x_n$ be a set of nodes in $[-1,1]$, and consider
$$\Pi(x)=(x-x_0)(x-x_1)\cdots(x-x_n),$$and
$$\hat \Pi(x) = \frac{T_{n+1}(x)}{2^{n}} = (x-\hat x_0)(x-\hat x_1)\cdots(x-\hat x_n).$$We have to prove that
$$\sup_{x \in [-1,1]} \lvert \hat\Pi(x) \rvert \leq \sup_{x \in [-1,1]} \lvert \Pi(x) \rvert.$$Assume by contradiction that $$\sup_{x \in [-1,1]} \lvert \Pi(x)\rvert < \sup_{x \in [-1,1]} \hat\Pi(x), $$ which can be rewritten $$\sup_{x \in [-1,1]} \lvert \Pi(x)\rvert < \sup_{x \in [-1,1]} \frac{\lvert T_{n+1}(x)\rvert}{2^{n}}.$$
From this and the properties of $T_{n+1}$ we then have that, for all $x\in [-1,1]$, $\displaystyle \lvert \Pi(x) \rvert < \frac{1}{2^{n}}$.
Let us now consider
$$D_{n}(x) = \Pi(x) - \hat\Pi(x) = \Pi(x) - \frac{ T_{n+1}(x)}{2^{n}},$$which is a polynomial of degree at most $n$ (since the coefficient of degree $n+1$ in both $\Pi$ and $\hat\Pi$ is $1$). Our goal is to show that $D_n=0$, which would be a contradiction. For $k=0,\ldots,n+1$ and $\hat y_k = \cos\left(\frac{k\pi}{n+1}\right)$, we have
$$\hat\Pi( \hat y_k) = \frac{ T_{n+1}(\hat y_k)}{2^{n}} = \frac{ (-1)^k}{2^{n}}.$$However, since $\displaystyle \lvert \Pi(x) \rvert < \frac{1}{2^{n}}$, we have that $D_{n}(\hat y_k)$ is positive for even $k$ and negative for odd $k$, $0\leq k\leq n+1$. In particular, $D_{n}$ has at least $n+1$ zeros by the intermediate value theorem, but $D_n$ is a polynomial of degree at most $n$, so it must be $0$. This is a contradiction ($\Pi \neq \hat\Pi$ because we assumed $\sup_{x \in [-1,1]} \lvert \Pi(x)\rvert < \sup_{x \in [-1,1]} \hat\Pi(x)$), and the theorem is proven.
In particular, we have $\|\hat \Pi\|_\infty \leq \|\bar \Pi\|_\infty$ for any number of nodes $n$, as suggested by the previous numerical experiment.
Complete the following cell in order to plot the interpolation polynomial of the Runge function on $[-1,1]$ for $n=10$ and $n=20$ Chebyshev nodes. You can use the compare_Pnf_f function. How do the results compare with what you obtained previously for equidistant nodes?
n1 = 10
n2 = 30
x1 = xhat(n1+1) # n1+1 Chebyshev nodes in [-1,1]
x2 = xhat(n2+1) # n2+1 Chebyshev nodes in [-1,1]
X = np.linspace(-1, 1, 1001) # the points at which f, P_n(f) and e_n(f) will be evaluated and plotted
# Plots of f, P_n(f) and e_n(f)
compare_Pnf_f(f_Runge, x1, X)
compare_Pnf_f(f_Runge, x2, X)


As expected, the interpolation polynomials obtained with Chebyshev nodes give a much better approximation of the Runge function than the one obtained with equidistant nodes: the oscillations close to the boundary disappeared, and it looks like $P_n(f)$ is now converging to $f$.
Compare also $f_1$ and the interpolation polynomial $P_n(f_1)$ obtained with Chebyshev nodes, for different values of $n$. Do the result differ from what you obtained previously with equidistant nodes?
n = 40 # degree of the interpolation polynomial
x = xhat(n+1) # n+1 Chebyshev nodes for the interpolation
X = np.linspace(-1,1,1001) # the points at which f, P_n(f) and e_n(f) will be plotted
compare_Pnf_f(f1, x, X)

On this example, the interpolation polynomials obtained with equidistant nodes did not converge to the function. With Chebyshev nodes, it seems like we do have convergence at first. However, when $n$ becomes too large ($\approx 50$), we also observe the apparition of oscillations, and the interpolation polynomial is no longer close to the function. One might think that these bad behavior when $n$ becomes too large is due to rounding errors.
Complete the following function ErrorCheb to compute the global interpolation error $E_n(f)$ for Chebyshev interpolation points and several values of $n$. In practice, you can approximate
by
$$ \max_{i\in I}\,\lvert f(X_i) - P_n(f)(X_i) \rvert, $$where $\left(X_i\right)_{i\in I}$ is a sufficiently fine discretization of $[-1,1]$.
Then, use this function in the subsequent cell to plot the evolution of $E_n(f)$ with $n$ (use a log scale), for the functions $f_1$, $f_2$, $f_3$ and $f_{Runge}$. Comment on the results.
def ErrorCheb(f, nmax, X):
"""
Approximates the global interpolation error E_n(f) = sup_{[-1,1]} |f-P_n(f)| for n=0,...,nmax,
by computing sup_{X_i in X} |f(X_i)-P_n(f)(X_i)|.
Here P_n(f) is the interpolation polynomial for Chebyshev nodes.
-----------------------
Inputs:
f : continuous function on [-1,1]
nmax : integer, largest n for which the error has to be computed
X : 1D array containing the points at which f and P_n(f) will be evaluated to compute E_n(f)
Output:
tab_Enf : 1D array containing [E_0(f), E_1(f), ..., E_{nmax}(f)]
"""
tab_n = np.arange(0, nmax+1) # values of n for which the error E_n(f) = sup |f-P_n(f)| has to be computed
tab_Enf = np.zeros(nmax+1) # Pre-allocation
for n in tab_n:
x = xhat(n+1) # n+1 Chebyshev nodes to compute the interpolant
y = f(x) # values of f at the nodes
a = interpVDM(x, y) # the coefficients of the interpolation polynomial P_n(f)
PnfX = evalHorner(a, X) # values of P_n(f) at the points stored in X
tab_Enf[n] = np.max(np.abs( PnfX - f(X) )) # computation of E_n(f)
return tab_Enf
## graphical study of the convergence
nmax = 40
X = np.linspace(-1,1,1001)
tab_Enf1 = ErrorCheb(f1, nmax, X)
tab_Enf2 = ErrorCheb(f2, nmax, X)
tab_Enf3 = ErrorCheb(f3, nmax, X)
tab_EnfRunge = ErrorCheb(f_Runge, nmax, X)
tab_n = np.arange(0, nmax+1)
plt.figure(figsize=(10, 6))
plt.plot(tab_n, tab_Enf2, marker='o', label='$f_2$')
plt.plot(tab_n, tab_Enf3, marker='o', label='$f_3$')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for Chebyshev nodes, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()
plt.figure(figsize=(10, 6))
plt.plot(tab_n, tab_Enf1, marker='o', label='$f_1$')
plt.plot(tab_n, tab_EnfRunge, marker='o', label='$f_{Runge}$')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for Chebyshev nodes, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()


We now seem to have convergence for all the different functions studied, although the speed of convergence varies a lot depending on the function. However, we still see that the error saturates and stops decreasing when $n$ becomes too large, which is again due to rounding errors, and to our choice of algorithms to compute the interpolation polynomial.
For the functions $f_1$ and $f_{Runge}$, still using Chebyshev nodes, try to make a precise conjecture as to how the global interpolation error behaves with respect to $n$. Hint: in both cases, try to plot the error using different scales until you find straight lines, and then maybe use polyfit. Is the convergence sublinear or linear?
## a more precise study of the convergence
nmax = 40
X = np.linspace(-1,1,1001)
tab_Enf1 = ErrorCheb(f1, nmax, X)
tab_Enf2 = ErrorCheb(f2, nmax, X)
tab_Enf3 = ErrorCheb(f3, nmax, X)
tab_EnfRunge = ErrorCheb(f_Runge, nmax, X)
tab_n = np.arange(0, nmax+1)
plt.figure(figsize=(10, 6))
plt.plot(tab_n[1:], tab_Enf1[1:], marker='o', label='$f_1$')
plt.plot(tab_n[1:], 1/tab_n[1:], marker='*', label='$1/n$')
plt.legend(fontsize = 18)
plt.xscale('log')
plt.yscale('log')
plt.title('Global interpolation error for Chebyshev nodes for $f_1$, log-log scale', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()
rho = (1+sqrt(26))/5
plt.figure(figsize=(10, 6))
plt.plot(tab_n, tab_EnfRunge, marker='o', label='$f_{Runge}$')
plt.plot(tab_n, 1/rho**tab_n, marker='*', label='$1/rho^n$')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for Chebyshev nodes for $f_{Runge}$, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()


It looks like the global interpolation error behaves like $\frac{cste}{n}$ for $f_1$, which would mean sublinear convergence, and like $\frac{cste}{\rho^n}$ for $f_{Runge}$, for $\rho\approx 1.2$, which would mean linear convergence. This approximate value of $\rho$ can be found using polyfit, see the cell below.
ab = np.polyfit(tab_n, np.log(tab_EnfRunge), 1) #Finding the coefficients of the line which better fits the data
a = ab[0] # the slope a
C = np.exp(a) # the convergence rate C
rho = 1/C
print("rho is approximately equal to ",rho)
rho is approximately equal to 1.2184633794890203
For the function $f_{Runge}$, one can actually prove that the global interpolation error does behave like $\frac{cste}{\rho^n}$, and compute the precise value of $\rho$, namely $\frac{1+\sqrt{26}}{5}$, but this again goes beyond the scope of this course.
Finally, for the functions $f_2$ and $f_3$, for which the interpolation polynomial converges for equidistant and Chebyshev nodes, plot the global error $E_n(f)$ versus $n$ on the same picture for both choices of nodes. Conclude.
## Comparison
nmax = 50
X = np.linspace(-1,1,1001)
tab_Enf2_Equi = ErrorEqui(f2, nmax, X)
tab_Enf3_Equi = ErrorEqui(f3, nmax, X)
tab_Enf2_Cheb = ErrorCheb(f2, nmax, X)
tab_Enf3_Cheb = ErrorCheb(f3, nmax, X)
tab_n = np.arange(0, nmax+1)
plt.figure(figsize=(20, 8))
plt.subplot(121)
plt.plot(tab_n, tab_Enf2_Equi, marker='o', label='Equidistant nodes')
plt.plot(tab_n, tab_Enf2_Cheb, marker='o', label='Chebyshev nodes')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for $f_2$, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f_2)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.subplot(122)
plt.plot(tab_n, tab_Enf3_Equi, marker='o', label='Equidistant nodes')
plt.plot(tab_n, tab_Enf3_Cheb, marker='o', label='Chebyshev nodes')
plt.legend(fontsize = 18)
plt.yscale('log')
plt.title('Global interpolation error for $f_3$, log scale for the error', fontsize = 18)
plt.xlabel('$n$',fontsize = 18)
plt.ylabel('$E_{n}(f_3)$',fontsize = 18)
plt.tick_params(labelsize=18)
plt.show()

Even in situations where the interpolation polynomial converges for both choices of nodes, Chebyshev nodes are better: the convergence is faster, and the rounding error have less impact.
We only dealt with interpolation at Chebyshev nodes on the interval $[-1,1]$, but this can easily be generalized on any interval $[a,b]$ via the affine bijection $x\mapsto a+\frac{x+1}{2}(b-a)$.
and the fact that the Chebyshev nodes minimize $\left\Vert \Pi_{x_0\ldots\,x_n} \right\Vert_\infty$. However, one can do even better for the Chebyshev nodes, and prove that, as soon as $f$ is a bit more than continuous (for example Lipschitz), then the interpolation polynomial at the Chebyshev nodes converges uniformly to $f$ (with a speed depending on the regularity of $f$). This proves that for the function $f_1$ considered previously, $P_n(f_1)$ does indeed converge to $f_1$ for Chebyshev nodes.
In the previous subsection, we have seen that rounding errors could produce some kind of instability in our algorithms when $n$ becomes large, especially with uniform interpolation nodes. Here we are going to see that the instability can already manifest itself for moderate values of $n$ in a slightly different context, namely noisy data.
Indeed, suppose that we want to interpolate a function $f$ at points $x_0,\ldots,x_n$, and suppose that the available values of $f$ at these points are not exact (think for example of noise due to experimental measurements). To model this phenomenon, when we compute the interpolation polynomial we are going to replace $f(x_k)$ by $f(x_k) + \epsilon_k$, with $\epsilon_k$ a random variable of small amplitude.
Obviously, we can no longer expect $P_n(f)$ to represent $f$ very accurately, but one would like the error to have roughly the same magnitude as the noise.
f = f2 # the function for which we do the test
eps = 0.05 # magnitude of the noise
def noise(x):
return eps * ( 2*np.random.rand(x.size)-1 ) # as many random values in [-eps,eps] as elements in x
n = 20 # degree of the interpolation polynomial
x_equi = np.linspace(-1, 1, n+1) # n+1 equidistant nodes for the interpolation
x_cheb = xhat(n+1) # n+1 Chebyshev nodes for the interpolation
X = np.linspace(-1,1,1001) # the points at which f and P_n(f) will be plotted
# Computation of the interpolation polynomials for noisy data and equidistant nodes
y_equi = f(x_equi) + noise(x_equi) # noisy values of f at the nodes
a_equi = interpVDM(x_equi, y_equi) # the coefficients of the interpolation polynomial P_n(f)
PnfX_equi = evalHorner(a_equi, X) # values of P_n(f) at the points stored in X
# Computation of the interpolation polynomials for noisy data and equidistant nodes
y_cheb = f(x_cheb) + noise(x_cheb) # noisy values of f at the nodes
a_cheb = interpVDM(x_cheb, y_cheb) # the coefficients of the interpolation polynomial P_n(f)
PnfX_cheb = evalHorner(a_cheb, X) # values of P_n(f) at the points stored in X
plt.figure(figsize=(20, 8))
plt.subplot(121)
plt.plot(X, f(X), label = 'Target function $f$')
plt.plot(x_equi, y_equi, marker='o', linestyle='', label = 'Noisy data set')
plt.plot(X, PnfX_equi, '--',label = 'Interpolation polynomial $P_n(f)$')
plt.legend(fontsize = 18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.title('Noisy data, equidistant nodes, n= %i' %n, fontsize = 18)
plt.subplot(122)
plt.plot(X, f(X), label = 'Target function $f$')
plt.plot(x_cheb, y_cheb, marker='o', linestyle='', label = 'Noisy data set')
plt.plot(X, PnfX_cheb, '--',label = 'Interpolation polynomial $P_n(f)$')
plt.legend(fontsize = 18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.title('Noisy data, Chebyshev nodes, n= %i' %n, fontsize = 18)
plt.show()

For the function $f_2$, we have already seen and proven that, without the noise, the interpolation polynomial gets really close to the function itself for both choices of nodes, at least until the rounding errors start to quick in.
However, when we add noise and increase the number of points (try taking $n=15,20,30...$) we observe the apparition of strong oscillations for the noisy case with equidistant nodes. The interpolation polynomial does not approximate well the noisy data in that case, even if the noise is small (you can also experiment with this by changing the value of the parameter eps in the above cell). This indicates that, for equidistant nodes, the interpolation is unstable. However, notice that for Chebyshev nodes, the interpolation seems stable, as the interpolation polynomial does approximate the noisy data well, even when we increase $n$ (at least at first). Of course we still observe some small differences between $f$ and $P_n(f)$ in that case, but they seem commensurate with the differences between the noisy data and $f$ itself. Again, the Chebyshev nodes are a much better choice than the equidistant nodes.
If we keep increasing $n$ (try for instance $n=50$), even in the case of Chebyshev nodes the error due to the noise starts getting amplified a lot, and the interpolation polynomial no longer fits the data well.
As we already alluded to earlier, the instability that occurs with Chehyshev nodes when $n$ becomes too large is due to our choice of algorithm to compute the interpolation polynomial. Better (more stable) algorithms exist, but they are beyond the scope of this lecture.
We now discuss another kind of approximation, namely piecewise interpolation. The idea here is to consider polynomial interpolation on subintervals. The degree of the approximation on each subinterval is fixed, and we try to improve the quality of the piecewise approximation by increasing the number of subintervals.
Let $(t_j)_{j=0,\ldots, m}$ be $m+1$ distinct given points in $[a,b]$ with $t_0=a$ and $t_m=b$. For the sake of simplicity, suppose that these points are ordered: $t_j<t_{j+1}$ for $j=0,\ldots, m-1$. We consider the corresponding subdivision of the interval:
$$ [a,b] = \bigcup_{j=0}^{m-1} [t_j,t_{j+1}]. $$The set of points $(t_j)_{j=0,\ldots, m}$ is said to be a mesh of the interval $[a,b]$ and we define the mesh size as:
$$h = \max_{j=0,\ldots, m-1}{\lvert t_{j+1} - t_j \rvert}.$$This parameter is supposed to go to zero: the smaller $h$, the smaller each of the subintervals of the subdivision.
The first idea is to use constant functions to approximate $f$ on each subinterval (i.e. polynomials of degree 0).
## Plots of several functions together with their P0 approximation
## we use the fact that plt.plot(x,y) plots lines between the points (x[k],y[k])
m = 21
t = np.linspace(-1,1,m+1) # uniform mesh
# the vector [t0, t1, t1, t2, t2, ... , t{m-1}, tm, tm] used to plot piece-wise constant functions
t_pw = np.zeros(2*m+1)
t_pw[0::2] = t
t_pw[1::2] = t[1:]
# points at which the target functions will be plotted
X = np.linspace(-1,1,1001)
fig = plt.figure(figsize = (20,16))
plt.subplot(2,2,1)
y1 = f1(t)
# create the vector [f(t0), f(t0), f(t1), f(t1), ... , f(t{m-1}), f(t{m-1}), f(t{m})]
y1_pw = np.zeros(2*m+1)
y1_pw[0::2] = y1
y1_pw[1::2] = y1[0:-1]
#plot the function
plt.plot(X, f1(X), label='Target function')
#plot the P0 interpolation
plt.plot(t, y1, marker='o', linestyle='', label = 'data set')
plt.plot(t_pw, y1_pw, '--', label='P0 approximation')
plt.title('$f_1$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,2)
y2 = f2(t)
# create the vector [f(t0), f(t0), f(t1), f(t1), ... , f(t{m-1}), f(t{m-1}), f(t{m})]
y2_pw = np.zeros(2*m+1)
y2_pw[0::2] = y2
y2_pw[1::2] = y2[0:-1]
#plot the function
plt.plot(X, f2(X), label='Target function')
#plot the P0 interpolation
plt.plot(t, y2, marker='o', linestyle='', label = 'data set')
plt.plot(t_pw, y2_pw, '--', label='P0 approximation')
plt.title('$f_2$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,3)
y3 = f3(t)
# create the vector [f(t0), f(t0), f(t1), f(t1), ... , f(t{m-1}), f(t{m-1}), f(t{m})]
y3_pw = np.zeros(2*m+1)
y3_pw[0::2] = y3
y3_pw[1::2] = y3[0:-1]
#plot the function
plt.plot(X, f3(X), label='Target function')
#plot the P0 interpolation
plt.plot(t, y3, marker='o', linestyle='', label = 'data set')
plt.plot(t_pw, y3_pw, '--', label='P0 approximation')
plt.title('$f_3$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,4)
yRunge = f_Runge(t)
# create the vector [f(t0), f(t0), f(t1), f(t1), ... , f(t{m-1}), f(t{m-1}), f(t{m})]
yRunge_pw = np.zeros(2*m+1)
yRunge_pw[0::2] = yRunge
yRunge_pw[1::2] = yRunge[0:-1]
#plot the function
plt.plot(X, f_Runge(X), label='Target function')
#plot the P0 interpolation
plt.plot(t, yRunge, marker='o', linestyle='', label = 'data set')
plt.plot(t_pw, yRunge_pw, '--', label='P0 approximation')
plt.title('$f_{Runge}$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.show()

It seems that the $\mathbb{P}^0$-approximation converges to the target function when $m$ goes to infinity, or equivalently, when the mesh size $h=\frac{1}{m}$ goes to $0$, even for Runge's function. However, the convergence seems slower than what we observed previously with interpolation of high degree, especially with Chebyshev nodes (for instance, for $m=50$ one can still see the difference between $\Pi^0 f$ and $f$ with the naked eye, which was not the case previously).
It turns out that the observed convergence can be proved under rather mild assumptions on $f$, and that we also get an error bound.
In particular, the global error $\sup_{x \in [a,b]} \lvert \Pi^0 f(x) - f(x) \rvert$ goes to $0$ when $h$ goes to $0$, and $\Pi^0 f(x)$ converges uniformly to $f$ on $[a,b]$.
Proof. Let us choose an $x$ in $[a,b]$. Since the point $x$ is in one of the subintervals, there exists an index $j_x$ with $0\leq j_x < m$ such that $x\in [t_{j_x},t_{j_x+1}]$. From the definition of $\Pi^0 f$ we get $\Pi^0 f(x) = f(t_{j_x})$. Then, from the Mean-Value theorem, we have the existence of $\xi_x\in [t_{j_x},x]$ such that
$$\lvert \Pi^0 f(x) - f(x) \rvert= \lvert f(t_{j_x}) - f(x) \rvert= \lvert (t_{j_x}-x) f'(\xi_x)\rvert \leq h \sup_{x\in [a,b]} |f'(x)|.$$This is true for any $x$ in $[a,b]$ and the upper bound does not depend on $x$. As a consequence we obtain the announced result:
$$ \sup_{x \in [a,b]} \lvert \Pi^0 f(x) - f(x) \rvert \leq h \sup_{x\in [a,b]} |f'(x)|.$$
The precision of the piecewise approximation can be increased by using affine approximations (that is, polynomials of degree 1 rather than 0) on each subinterval.
## Plots of several functions together with their P1 approximation
m = 21
t = np.linspace(-1,1,m+1) # uniform mesh
# points at which the target functions will be plotted
X = np.linspace(-1,1,1001)
fig = plt.figure(figsize = (20,16))
plt.subplot(2,2,1)
y1 = f1(t)
plt.plot(X, f1(X), label='Target function')
plt.plot(t, y1, marker='o', linestyle='', label = 'data set')
plt.plot(t, y1, '--', label='P1 approximation')
plt.title('$f_1$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,2)
y2 = f2(t)
plt.plot(X, f2(X), label='Target function')
plt.plot(t, y2, marker='o', linestyle='', label = 'data set')
plt.plot(t, y2, '--', label='P1 approximation')
plt.title('$f_2$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,3)
y3 = f3(t)
plt.plot(X, f3(X), label='Target function')
plt.plot(t, y3, marker='o', linestyle='', label = 'data set')
plt.plot(t, y3, '--', label='P1 approximation')
plt.title('$f_3$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.subplot(2,2,4)
yRunge = f_Runge(t)
plt.plot(X, f_Runge(X), label='Target function')
plt.plot(t, yRunge, marker='o', linestyle='', label = 'data set')
plt.plot(t, yRunge, '--', label='P1 approximation')
plt.title('$f_{Runge}$', fontsize=18)
plt.legend(fontsize=18)
plt.xlabel('x', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.show()

We also observe the convergence of the $\mathbb{P}^1$-approximation to the target function when $m$ goes to infinity, or equivalently, when the mesh size $h=\frac{1}{m}$ goes to $0$, and in most cases the error seems to decrease faster than with the $\mathbb{P}^0$-approximation.
These observations are validated by the following theorem.
In particular, the global error $\sup_{x \in [a,b]} \lvert \Pi^0 f(x) - f(x) \rvert$ goes to $0$ when $h$ goes to $0$, and $\Pi^0 f(x)$ converges uniformly to $f$ on $[a,b]$.
Proof. [$\star$] Let us choose an $x$ in $[a,b]$. Since the point $x$ is in one of the subintervals, there exists an index $j_x$ with $0\leq j_x < m$ such that $x\in [t_{j_x},t_{j_x+1}]$. Notice that, on $[t_{j_x},t_{j_x+1}]$, $\Pi^1 f$ is the Lagrange interpolation polynomial interpolating $f$ at the nodes $t_{j_x}$ and $t_{j_x+1}$. Therefore, one can use the error approximation theorem for Lagrange interpolation and get the existence of $\xi_x\in[t_{j_x},t_{j_x+1}]$ such that
$$f(x) - \Pi^1 f(x) = \frac{(x-t_{j_x})(x-t_{j_x+1})}{2!} f''(\xi_x).$$The maximum of $\left\vert (x-t_{j_x})(x-t_{j_x+1}) \right\vert$ on the interval $[t_{j_x},t_{j_x+1}]$ is reached at $(t_{j_x}+t_{j_x+1})/2$ and is equal to $\left( (t_{j_x+1}-t_{j_x})/2 \right)^2 \leq \frac{h^2}{4}$ so that we obtain the following upper-bound:
$$\lvert \Pi^1 f(x) - f(x) \rvert \leq \frac{h^2}{8} \sup_{x\in [a,b]} |f''(x)|.$$This being true for any $x$ in $[a,b]$, the theorem is proved.
for which we have sublinear convergence, as introduced in Chapter 1, since in both cases $$ \frac{\beta_{m+1}}{\beta_m} \underset{m\to\infty}{\longrightarrow} 1. $$
 |
 |
Adrien-Marie Legendre (1752 - 1833) and Carl Friedrich Gauss (1777 - 1855). The method of least squares grew out of the fields of astronomy and geodesy, as scientists and mathematicians sought to provide solutions to the challenges of navigating the Earth's oceans. To do so, the accurate description of the behavior of celestial bodies was the key to enabling ships to sail in open seas, where sailors could no longer rely on land sightings for navigation. A seminal method, called the method of average, was used for example by the French scientist Pierre-Simon Laplace to study the motion of Jupiter and Saturn. The first clear and concise exposition of the method of least squares was published by the French mathematician Adrien-Marie Legendre in 1805 (no portrait known apart from this caricature...). In 1809, the German mathematician Carl Friedrich Gauss published his method of calculating the orbits of celestial bodies. In that work he claimed to have been in possession of the method of least squares since 1795. This naturally led to a priority dispute with Legendre. However, to Gauss's credit, he went beyond Legendre and succeeded in connecting the method of least squares with the principles of probability and to the normal distribution.
Suppose now that you are a case where:
With the Lagrange interpolation that we have seen previously, the degree of the interpolation polynomial is prescribed by the number of points, and so having a large data set in not compatible with an approximation of low degree. The piece-wise interpolation techniques that we just saw are also not suitable, because they do not satisfy the requirement of having a single model for the whole data.
We present here a method allowing to deal with these problems.
Assume that a dataset $(x_k,y_k)_{k=0..n}$ is given. We want to find a polynomial $Q_m$ with degree at most $m$ to approximate this data, but with $m\ll n$. This means that we will typically not be able to find $Q_m$ such that $Q_m(x_k) = y_k$ for $k=0,\ldots,n$, as there are too many equations ($n+1$) compared to the number of unknown (the $m+1$ coefficients of $Q_m$). Therefore, we have to settle for finding $Q_m$ such that $Q_m(x_k)$ is "close to" $y_k$ for $k=0,\ldots,n$.
Here, we consider the least squares approximation, which means that $Q_m$ has to be "close to" the data in the following sense: $Q_m$ is a polynomial of degree at most $m$ minimizing the following functional $J$ among all the polynomials $Q$ of degree at most $m$
$$ J(Q) = \sum_{k=0}^n (Q(x_k) - y_k)^2. $$In that sense, $J(Q)$ measures how $Q$ is close to the data. Other choices for $J$ are possible. The least squares choice provides a convex function $J$ for which the existence and uniqueness of the minimizer can be proved.
Assume that the dataset $(x_k,y_k)_{k=0..n}$ is given and you want to find a constant polynomial $Q(x)=a$ such that $Q$ minimizes $J$ over the set of constant polynomials.
The unknown is the coefficient $a$, and the problem comes back to finding the constant $a^*$ minimizing the functional
$$ J(a) = \sum_{k=0}^n (Q(x_k) - y_k)^2 = \sum_{k=0}^n (a - y_k)^2. $$Proof. In that case, the function $a \rightarrow J(a)$ is a polynomial of degree 2 with a positive leading coefficient, which implies that there exists a unique $a^*$ minimizing $J$ and that $a^*$ is solution to
$$J'(a^*) = 0.$$This gives
$$\sum_{k=0}^n 2 (a^* - y_k) = 0,$$and finally $a^*$ is the mean value of the data:
$$a^* = \frac{1}{n+1} \sum_{k=0}^n y_k.$$
Assume that the dataset $(x_k,y_k)_{k=0..n}$ is given and you now want to find a linear polynomial $Q(x)=ax$ such that $Q$ minimizes $J$ over the set of linear polynomials.
Again, the unknown is the coefficient $a$ and the problem comes back to finding the constant $a^*$ minimizing the functional
$$ J(a) = \sum_{k=0}^n (Q(x_k) - y_k)^2 = \sum_{k=0}^n (a\,x_k - y_k)^2. $$Proof. The function $a \rightarrow J(a)$ is again a polynomial of order 2 with a positive dominant coefficient, which implies that there exists a unique $a^*$ minimizing $J$ and that $a^*$ is solution to
$$J'(a^*) = 0.$$This gives
$$\sum_{k=0}^n 2 (a^* x_k - y_k)\, x_k = 0,$$which provides an explicit formula for $a^*$ in terms of the data:
$$a^* = \frac{\displaystyle\sum_{k=0}^n x_k \, y_k}{\displaystyle\sum_{k=0}^n x_k^2}.$$
## Computation of parameters astar for a linear model, using least squares
## input : x = vector containing the nodes x0...xn
## y = vector containing the values y0...yn
## output : astar = approximation of a
def LinearReg(x,y):
"""
Computation of the parameter a* of a linear model, using least squares
----------------------------------------
Inputs:
x : vector containing the nodes x0...xn
y : vector containing the values y0...yn
Output:
astar : approximation of the linear coefficient
"""
return np.sum(x*y) / np.sum(x*x)
# size of the dataset
n = 100
# original model : f(x) = ax
a = 3
x = np.linspace(0,1,n)
y = a*x
# compute the data : add noise to the original model
noiseSize = 0.2
noise = ( 2*np.random.rand(x.size) - 1 ) * noiseSize # uniform in [-noiseSize,noiseSize]
data = y + noise
# compute the linear regression
astar = LinearReg(x,data)
# approximated model
ystar = astar*x
# computation of the value of J(astar,bstar)
J = np.sum( (ystar - y)**2 )
#plot
plt.figure(figsize = (10,6))
plt.plot(x, y, label='Original model, a ='+str(a))
plt.plot(x, data,marker='o', linestyle='', label='Noisy data set')
plt.plot(x, ystar, label='Linear regression, a* ='+str(round(astar,4)))
plt.xlim(0,1)
plt.ylim(0,a)
plt.xlabel('$x$', fontsize = 18)
plt.ylabel('$y$', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.legend(fontsize = 18)
plt.title('Linear regression, n ='+str(n)+', J(a*) ='+str(round(J,4)), fontsize = 18)
plt.show()

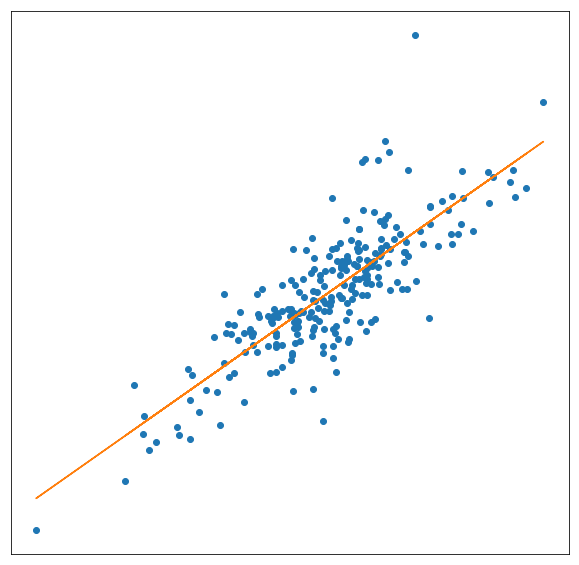
Assume that the dataset $(x_k,y_k)_{k=0..n}$ is given and you now want to find an affine polynomial $Q(x)=ax+b$ such that $Q$ minimizes $J$ over the set of affine polynomials.
In that case, there are two unknown coefficients $a$ and $b$. The problem comes back to finding the constants $(a^*,b^*)$ minimizing the functional
$$ J(a,b) = \sum_{k=0}^n (Q(x_k) - y_k)^2 = \sum_{k=0}^n (ax_k + b - y_k)^2. $$where
$$ \bar{x} = \frac{1}{n+1}\sum_{k=0}^n x_k,\quad{} \bar{y} = \frac{1}{n+1}\sum_{k=0}^n y_k,\quad{} \overline{xy} = \frac{1}{n+1}\sum_{k=0}^n x_k y_k \quad{}\text{and}\quad{} \overline{x^2} = \frac{1}{n+1}\sum_{k=0}^n x^2_k. $$Proof. [$\star$] We want to find $(a^*,b^*)$ such that
$$\forall a,b\quad{} J(a^*,b^*)\leq J(a,b).$$For any $(a^*,b^*)$, we can write
$$J(a,b) = \sum_{k=0}^n (a^*x_k + b^* - y_k + (a-a^*)x_k + (b-b^*) )^2,$$and expand this expression to get
\begin{align} J(a,b) & = \sum_{k=0}^n (a^*x_k + b^* - y_k)^2 \nonumber\\ &\quad{} + \sum_{k=0}^n 2(a^*x_k + b^* - y_k)((a-a^*)x_k + (b-b^*)) + \sum_{k=0}^n ((a-a^*)x_k + (b-b^*))^2 \\ & = J(a^*,b^*) \nonumber\\ &\quad{} + \left(2\sum_{k=0}^n (a^*x_k^2 + b^*x_k - x_ky_k)\right) (a-a^*) + \left(2\sum_{k=0}^n (a^*x_k + b^* - y_k)\right) (b-b^*) \nonumber\\ &\quad{} + \sum_{k=0}^n ((a-a^*)x_k + (b-b^*))^2. \end{align}Let us now assume that $a^*$ and $b^*$ are such that $\sum_{k=0}^n (a^*x_k^2 + b^*x_k - x_ky_k)\neq 0$. Then, taking $b=b^*$ and $a$ close to $a^*$, we have
$$J(a,b^*) = J(a^*,b^*) + \left(2\sum_{k=0}^n (a^*x_k^2 + b^*x_k - x_ky_k)\right) (a-a^*) + o(a-a^*),$$and we see that $J(a^*,b^*)$ cannot be the minimum of $J$: taking $a$ a bit below $a^*$ (or a bit above, depending on the sign of $\sum_{k=0}^n (a^*x_k^2 + b^*x_k - x_ky_k)$), we would get that $J(a,b^*)$ is smaller than $J(a^*,b^*)$. Similarly, if $\sum_{k=0}^n (a^*x_k + b^* - y_k) \neq 0$, we see by taking $a=a^*$ and $b$ close to $b^*$ that $J(a^*,b^*)$ cannot be the minimum of $J$.
We have just shown that, if $J$ reaches its minimum at $(a^*,b^*)$, then we must have
$$\left\{\begin{aligned} &\sum_{k=0}^n (a^*x_k^2 + b^*x_k - x_ky_k) & = 0 \\ &\sum_{k=0}^n (a^*x_k + b^* - y_k) & = 0 \end{aligned} \right. $$Conversely, if these two conditions are met, then from the expansion obtained just above we get
$$J(a,b) = J(a^*,b^*) + \sum_{k=0}^n ((a-a^*)x_k + (b-b^*))^2,$$and since the last term is nonnegative we indeed have $J(a^*,b^*)\leq J(a,b)$ for all $a$ and $b$. We have thus found two necessary and sufficient conditions for $(a^*,b^*)$ to be a minimizer of $J$. (Once you will have learned about optimizing functions of several variables, you'll be able to do the above part of the proof in two lines.) Next, notice that these two conditions can be rewritten as
$$\left\{\begin{aligned} &\left(\sum_{k=0}^n x_k^2\right) a^* + \left(\sum_{k=0}^n x_k\right) b^* = \sum_{k=0}^n x_ky_k \\ &\left(\sum_{k=0}^n x_k\right) a^* + (n+1) b^* = \sum_{k=0}^n y_k \end{aligned} \right. $$That is, we want $(a^*,b^*)$ to solve the linear system
$$ M \left(\begin{array}{l} a^* \\ b^* \end{array} \right) = V \quad{} \text{where}\quad{} M = \left(\begin{array}{ll} \displaystyle \sum_{k=0}^n x_k^2 &\displaystyle \sum_{k=0}^n x_k \\ \displaystyle \sum_{k=0}^n x_k &\displaystyle (n+1)\end{array}\right) \quad{} \text{and}\quad{} V = \left(\begin{array}{l} \displaystyle\sum_{k=0}^n x_k y_k \\ \displaystyle\sum_{k=0}^n y_k \end{array} \right). $$The determinant of $M$ is equal to $(n+1)\sum_{k=0}^n x_k^2 - \left(\sum_{k=0}^n x_k\right)^2$. However, by the Cauchy-Schwarz inequality
$$ \left(\sum_{k=0}^n x_k\right)^2 = \left(\sum_{k=0}^n x_k \times 1 \right)^2 \leq \left(\sum_{k=0}^n x_k^2 \right) \left(\sum_{k=0}^n 1^2 \right) = (n+1) \sum_{k=0}^n x_k^2, $$with equality only if all the $x_k$ are equal, which is excluded by the assumption. Therefore the determinant of $M$ is positive and $M$ is invertible. Hence, the solution $(a^*,b^*)$ of this linear system is unique, and by solving it we find the announced formula.
def AffineReg(x,y):
"""
Computation of parameters a* and b* of an affine model, using least squares
----------------------------------------
Inputs:
x : vector containing the nodes x0...xn
y : vector containing the values y0...yn
Output:
astar, bstar : the coefficients of the model (astar * x + bstar)
"""
n = x.size
mean_x = np.sum(x)/n
mean_y = np.sum(y)/n
mean_xy = np.sum(x*y)/n
mean_xx = np.sum(x**2)/n
astar = (mean_xy-mean_x*mean_y) / (mean_xx-mean_x**2)
bstar = mean_y - astar*mean_x
return astar, bstar
# size of the dataset
n = 100
# original model : f(x) = ax +b
a = 3
b = 2
x = np.linspace(0,1,n)
y = a*x + b
# compute the data : add noise to the original model
noiseSize = 0.2
noise = (-1 + 2*np.random.rand(x.size)) * noiseSize # uniform in [-noiseSize,noiseSize]
data = y + noise
# compute the affine regression
astar, bstar = AffineReg(x, data)
# approximated model
ystar = astar*x + bstar
# computation of the value of J(astar,bstar)
J = np.sum( (ystar - y)**2 )
#plot
fig = plt.figure(figsize = (10,6))
plt.plot(x,y,label='original model, a ='+str(a)+', b ='+str(b))
plt.plot(x,data,marker='o',linestyle='',label='data set')
plt.plot(x,ystar,label='affine regression, a* ='+str(round(astar,4))+', b* ='+str(round(bstar,4)))
plt.xlim(0,1)
plt.ylim(b,a+b)
plt.xlabel('$x$', fontsize = 18)
plt.ylabel('$y$', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.legend(fontsize = 18)
plt.title('Affine regression, n ='+str(n)+', J(a*,b*) ='+str(round(J,4)),fontsize = 12)
plt.show()

The necessary and sufficient conditions for having a minimum for such a functional, which are given by $\nabla J(a_0^*,a_1^*,\ldots, a_m^*) = 0$, give rise to a linear system for the optimal coefficients $a_0^*,a_1^*,\ldots, a_m^*$.
numpy.polyfit, which we have already used previously.Check that your function AffineReg gives approximately the same output as np.polyfit with degree $1$.
# size of the dataset
n = 100
# original model : f(x) = ax +b
a = 3
b = 2
x = np.linspace(0, 1, n)
y = a*x + b
# compute the data : add noise to the original model
noiseSize = 0.2
noise = (-1 + 2*np.random.rand(x.size)) * noiseSize # uniform in [-noiseSize,noiseSize]
data = y + noise
# compute the affine regression
astar, bstar = AffineReg(x, data)
# using polyfit
apf, bpf = np.polyfit(x, data, 1)
print("relative error for a*:", np.abs((astar-apf)/apf))
print("relative error for b*:", np.abs((bstar-bpf)/bpf))
relative error for a*: 1.7593571741833593e-15 relative error for b*: 6.721436171567256e-16
First, recall that we want to model the evolution of the world population, using the data set given in the introduction. The first objective is to estimate the population at year 1951, the second one is to determinate the year for which the population was equal to 2.2 billions. Here is the available data.
yearsData = np.array([1900., 1927., 1955., 1960.])
popData = np.array([1.6, 2, 2.772242535, 3.033212527])
plt.figure(figsize=(10,6))
plt.plot(yearsData,popData,linestyle='',marker="o")
plt.title('Evolution of the world population from 1900 to 1960', fontsize = 18)
plt.xlabel('Years', fontsize = 18)
plt.ylabel('Billions', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.show()

We want to approximate the population using a polynomial $P$. To evaluate the population in 1951, we will just have to evaluate the polynomial $P$ at $x = 1951$. To determine the year at which the population was equal to $2.2$ billions, we can use the root-finding methods studied in the previous cycle to find the zero of $P(x) - 2.2$.
To compute a polynomial approximating the data, we use the Lagrange polynomial approximation.
Xyear = np.linspace(1900, 1960, 61) #set of years for the plot
xyear = yearsData #nodes of the interpolation = [1900 1927 1955 1960]
y = popData #values at the nodes
a = interpVDM(xyear,y)
PX = evalHorner(a, Xyear) #computations of the corresponding interpolation polynomial
# We plot the interpolating curve
plt.figure(figsize=(10,6))
plt.plot(Xyear, PX, label='Polynomial interpolation')
plt.plot(yearsData, popData, linestyle='', marker = 'o', label='data')
plt.title('Lagrange interpolation of the world population', fontsize = 18)
plt.legend(fontsize = 18)
plt.xlabel('year', fontsize = 18)
plt.ylabel('Billions', fontsize = 18)
plt.tick_params(labelsize = 18)
plt.show()

year = 1951
popTarget = 2.583816786
pop = evalHorner(a, year)
print('According to Lagrange method, there were',pop,'billions of human beings in',year, '\nrelative error:',100*abs(pop-popTarget)/popTarget,'%')
According to Lagrange method, there were 2.5977165103249718 billions of human beings in 1951 relative error: 0.5379531706847532 %
We now want to use this Lagrange polynomial $P$ to estimate the year at which the population was equal to $2.2$ billions. To do so, we use the bisection method that we implemented in the previous cycle to find a root of the function $f(x) = P(x)-2.2$
def Bisection(f, a0, b0, k_max, eps):
"""
Bisection algorithm with stopping criterion based on the error bound
-----------------------
Inputs:
f : name of the function
a0, b0 : initial interval I_0 with f(a_0)f(b_0)<0
k_max : maximal number of iterations
eps : tolerance for the stopping criterion
Output:
x = the sequence x_k of mipoints of I_k
"""
x = np.zeros(k_max+1) # create vector x of zeros with size K+1
k = 0 # initialize k
a = a0 # initialize a
b = b0 # initialize b
x[0] = (a+b)/2 # initialize x_0
while (b0-a0)/(2**k) > eps and k < k_max :
if f(a) * f(x[k]) < 0 :
b = x[k]
else:
a = x[k]
k = k+1
x[k] = (a+b)/2
return x[:k+1] #removes the extra zeros and outputs exactly the computed x_k
## f(x) = P(x) - 2.2
def f(y):
return evalHorner(a,y) - 2.2
## initialization of the parameters of the bisection method
a0 = 1930
b0 = 1960
k_max = 50
eps = 1e-10
x = Bisection(f, a0, b0, k_max, eps)
x = x[-1]
year = floor(x)
months = ['Jan.','Feb.','Mar.','Apr.','May','June','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.']
m = months[floor((x-year)*12)]
print('According to the Lagrange approximation, the population went above',2.2,'billions in',m,'of',year)
According to the Lagrange approximation, the population went above 2.2 billions in Jan. of 1938
Recall we want to compute
$$\pi=4\int_{0}^{1}d_{atan}(x)dx $$where
$$ d_{atan}: \left\{\begin{array}{l} \mathbb{R} &\rightarrow &\mathbb{R} \\ x &\rightarrow &\frac{1}{1+x^2} \end{array}\right. $$To do so, we compute a an approximation of $d_{atan}$, and approximate the original integral by the integral of the approximation.
Use an approximation of $d_{atan}$ of your choice to estimate the above integral, and therefore $\pi$. You can for instance use a Lagrange polynomial interpolation of high degree, or a piece-wise approximation of low degree on a mesh with small mesh-size $h$.
A piece-wise approximation is probably easier to use here, because computing the integral of a piecewise constant of linear function is straightforward, but it will not converge very fast (you have to use a very fine mesh to get an accurate results).
On the other hand, a Lagrange polynomial interpolation with Chebyshev nodes will give a very accurate result, but there is a little bit of pen-and-paper work to be done first, as we will need to compute integrals of polynomials of higher degree.
This is the so-called rectangle rule for approximating integrals, which we will study in more details in the next chapter. $\mathbb{P}^1$ approximation can be used in a similar fashion, and gives rise to more accurate formula.
to get back to the interval $[-1,1]$. Then, assuming we have computed the coefficients of $P_n(f)$ interpolating $d_{atan}$, that is $$ P_n(f)(x) = \sum_{k=0}^n a_k x^k, $$ we can approximate $\pi$ by $$ 2\int_{-1}^{1}P_n(f)(x)dx = 2 \sum_{k=0}^n a_k \int_{-1}^{1}x^k dx = 2 \sum_{k=0}^n a_k \frac{1+(-1)^k}{k+1}. $$
We test both methods in the subsequent cells, and compare to obtained results to the approximation of $\pi$ used by Python.
def datan(x):
return 1/(1+x**2)
m_P0= 50 #number of subintervals for the mesh
mesh = np.linspace(0, 1, m_P0+1)
#approximation of pi using the P0 approximation of datan
pi_P0 = 4* 1/m_P0* np.sum(datan(mesh[:-1:]))
n_Lagrange = 50 #degree of the Lagrange interpolation polynomial
nodes = xhat(n_Lagrange+1)
a = interpVDM(nodes, datan(nodes))
tab_k = np.arange(0, n_Lagrange+1, dtype='float')
#approximation of pi using the interpolation of datan at Chebyshev nodes
pi_Lagrange = 2 * np.sum( a * (( 1 + (-1)**tab_k) / (tab_k + 1)) )
print('Approximation of pi stored in by Pyhton:', pi)
print('Approximation of pi using a P0 approximation:', pi_P0)
print('Approximation of pi using Lagrange interpolation:', pi_Lagrange)
Approximation of pi stored in by Pyhton: 3.141592653589793 Approximation of pi using a P0 approximation: 3.161525986923254 Approximation of pi using Lagrange interpolation: 3.1415926535897936
Recall that, being given the values of the market return $(R^m_k)_{k=0..n-1}$ and an asset return $(R_k)_{k=0..n-1}$ for $n$ days, one wants to estimate the parameters $\alpha$ and $\beta$ in order to model the behaviour of the corresponding asset as
$$ R_k = \alpha + \beta \, R^m_k. $$We use the least square approximation method to estimate these parameters for the data set $(x_k,y_k)_{k=0..n-1}=(R_k^m,R_k)_{k=0..n-1}$
The file Data_market.csv records the CAC 40 index and other assets returns from January 2015 to December 2015. The CAC 40 is a benchmark French stock market index and represents the variation of the whole market.
Data used come from https://www.abcbourse.com/download/historiques.aspx .
The data contains the daily asset return for the companies of the CAC40. A column corresponds to a given company and a row to a given day. The market return can be found in the last column.
The data set can be explored using pandas python library designed to manage data sets. For example, a column can be extracted from the data set using its name, given in the first row of the column.
We focus on the asset "Société Générale", referenced as "Societe.Generale" in the dataset.
## Load data
import pandas as pd # package for managing datasets
Namefile = "Data_market.csv"
Data = pd.read_csv(Namefile,sep=",")
Data.drop(['Unnamed: 0'],axis=1,inplace=True)
print(Data.head())
Dates Accor.Hotels Air.Liquide Airbus Alstom Axa \
0 2015-01-05 -0.012959 -0.031456 0.003006 -0.025437 -0.037881
1 2015-01-06 -0.021146 -0.008380 0.022905 0.000572 -0.010935
2 2015-01-07 0.004983 0.004505 0.025714 0.011756 0.010663
3 2015-01-08 0.019824 0.041231 0.033509 0.017934 0.040506
4 2015-01-09 -0.000813 -0.022707 -0.014817 -0.006688 -0.022716
Bnp.Paribas Bouygues Cap.Gemini Carrefour ... Societe.Generale \
0 -0.049772 -0.037670 -0.013396 -0.049668 ... -0.045712
1 -0.026502 -0.007638 -0.039369 -0.007995 ... -0.017922
2 -0.016844 0.011607 0.004199 -0.001057 ... -0.010757
3 0.031905 0.029529 0.028064 0.044461 ... 0.028678
4 -0.034128 -0.009915 0.006093 -0.034781 ... -0.011313
Solvay Technip Total Unibail.Rodamco Valeo Veolia.Environ. \
0 -0.040841 -0.048455 -0.061713 -0.008068 -0.016094 -0.025169
1 -0.007994 0.013650 -0.001502 0.001429 -0.015358 -0.014065
2 -0.007583 -0.004002 0.022417 0.014175 0.004483 0.007760
3 0.040556 0.021091 0.037854 0.036619 0.050398 0.018451
4 -0.024510 -0.013103 -0.031992 -0.018718 0.008471 0.014044
Vinci Vivendi Rnd.Market.Index
0 -0.034604 -0.020645 -0.033704
1 -0.010999 -0.016778 -0.006799
2 0.036203 0.002018 0.007133
3 0.034401 0.022921 0.035227
4 -0.000215 -0.002713 -0.019225
[5 rows x 39 columns]
## Set parameters
asset_name = 'Societe.Generale' #The asset
market_index_name = 'Rnd.Market.Index' # Represents Rk^m
marketReturn = Data[market_index_name] # The market return for each k: x_k
assetReturn = Data[asset_name] # The asset return at day k: y_k
## Compute alpha and beta
beta_star, alpha_star = AffineReg(marketReturn, assetReturn)
## plot the results
fitted_values = alpha_star + beta_star * marketReturn # Affine model for the asset return
error_vect = assetReturn - fitted_values
error = np.sum(error_vect**2)
plt.figure(figsize = (10,6))
plt.plot(marketReturn, fitted_values, label= 'Affine regression')
plt.plot(marketReturn, assetReturn, marker='o', linestyle='', label='data set')
plt.legend(fontsize = 18)
plt.title(r'Société Générale, $(\alpha,\beta)$ =('+str(round(alpha_star,4))+','+str(round(beta_star,4))+'), error is ='+str(round(error,4)), fontsize = 18)
plt.grid()
plt.xlabel('Market return', fontsize=18)
plt.ylabel('Asset return', fontsize=18)
plt.tick_params(labelsize = 18)
plt.show()

We saw in the previous estimations that the risk $\alpha$ was very small (it is the the intercept of the previous curve with the $y$-axis). This encourages us to simplify the CAPM model in a linear model:
$$ R_k = \beta \, R^m_k. $$and estimate only one parameter $\beta$ using linear regression.
## Set parameters
asset_name = 'Societe.Generale'
market_index_name = 'Rnd.Market.Index'
y = Data[asset_name]
x = Data[market_index_name]
## Plot the result
beta_star = LinearReg(x,y)
fitted_values = beta_star*x
error_vect = y - fitted_values
error = np.sum(error_vect**2)
plt.figure(figsize = (10,6))
plt.plot(x, y, marker='o', linestyle='', label='data set')
plt.plot(x, fitted_values, label='Linear regression')
plt.legend(fontsize = 18)
plt.title(r'Société Générale, $\beta$ ='+str(round(beta_star,4))+', error is ='+str(round(error,4)), fontsize = 18)
plt.grid()
plt.xlabel('Market return', fontsize=18)
plt.ylabel('Asset return', fontsize=18)
plt.tick_params(labelsize = 18)
plt.show()

Consider the linear model and suppose you computed $\beta^*$ and you want to know how confident you can be using this value to model the behaviour of the asset.
For any array $x$, we let $ \text{E}(x) = \frac{\sum_{k} x_k}{n}$ be the average value. If $R^m = (R_k^m)_{k=0..n-1}$ is the vector of return values of the market at each day $k$, then $E(R^m)$ is the average return value of the market over $n$ days. Similarly, for a given asset in the portfolio, $\text{E}(R)$ is its average return over the same period.
Using linear regression, we have found a linear model with parameter $\beta^*$ to approximate the return of the asset from the market return:
$$ R_k \approx \beta^* R^m_k \qquad{} k=0,\ldots,n-1. $$Using this model, we get that
$$ \text{E}(R) \approx \beta^*\, \text{E}(R^m), $$and we can then compare this approximation $\beta^*\, \text{E}(R^m)$ given by the model to the exact value $\text{E}(R)$ computed from the data.
This can be observed graphically using the "Security Market line" (SML) defined by
$$ (SML) \; : \; \beta \mapsto \beta\, \text{E}(R^m). $$For a given asset in the portfolio, if the point $(\beta^*, E(R))$ is above (resp. below) the line, it is under-estimated (resp. over-estimated) by the model.
This is what is done below with the different assets of the CAC40 dataset.
## Compute the data needed for the security market line
def Security_market_line(Data):
assets_name = list(Data)[1:-1]
size = len(assets_name)
x = Data[market_index_name] # the values R^m_k, k=0,...,n-1
Res = pd.DataFrame(np.zeros((size,3)), columns=['beta','Fit.val','Average.val'])
for asset_index in range(size): # asset_index = 0
asset_name = assets_name[asset_index]
y = Data[asset_name] # the values R_k, k=0,...,n-1, for the asset undere consideration
beta_star = LinearReg(x,y)
Res['beta'][asset_index] = beta_star # the estimated value of beta for this asset
Res['Fit.val'][asset_index] = beta_star*np.mean(x) # the corresponding approximation beta*E(R^m) of the average return of the asset
Res['Average.val'][asset_index] = np.mean(y) # the actual average return of the asset
assets_name = pd.DataFrame(assets_name, columns = ['Name'])
Res = pd.concat([assets_name,Res],axis=1)
return Res
## Plot
Res = Security_market_line(Data)
print(Res)
plt.figure(figsize = (16,8))
plt.plot(Res['beta'], Res['Average.val'], marker='o', linestyle='', label='data set')
plt.plot(Res['beta'], Res['Fit.val'], linewidth=5, label='Security Market line')
size = Res.shape[0]
for index in range(size): ## write names of assets
name = Res['Name'][index].split('.')[0]
x = Res['beta'][index]
y = Res['Average.val'][index]
plt.annotate(name, (x,y), fontsize=18)
plt.text(0.6,0.0012,"undervalued assets", fontsize=22, color='r')
plt.text(1.07,-0.0003,"overvalued assets", fontsize=22, color='r')
plt.legend(fontsize = 15)
plt.title('Checking the model against the data', fontsize = 18)
plt.xlabel(r'$\beta$', fontsize=18)
plt.ylabel('Average return', fontsize=18)
plt.tick_params(labelsize = 18)
plt.grid()
plt.show()
Name beta Fit.val Average.val 0 Accor.Hotels 1.026968 0.000349 0.000277 1 Air.Liquide 1.001062 0.000340 0.000086 2 Airbus 1.164138 0.000395 0.001572 3 Alstom 0.560532 0.000190 0.000184 4 Axa 1.067993 0.000363 0.001092 5 Bnp.Paribas 1.055432 0.000359 0.000216 6 Bouygues 0.780770 0.000265 0.000771 7 Cap.Gemini 0.897455 0.000305 0.001386 8 Carrefour 1.020038 0.000347 0.000239 9 Credit.Agricole 0.940770 0.000320 -0.000007 10 Danone 0.873758 0.000297 0.000570 11 Engie 0.938485 0.000319 -0.000659 12 Essilor.Intl 1.007121 0.000342 0.000920 13 Kering 1.032809 0.000351 0.000005 14 Klepierre 0.777030 0.000264 0.000553 15 Legrand.SA 0.851506 0.000289 0.000719 16 L.oreal 1.027396 0.000349 0.000480 17 Lvmh 1.205579 0.000410 0.000400 18 Michelin 0.801512 0.000272 0.000656 19 Orange 1.128273 0.000383 0.000379 20 Pernod.Ricard 0.828676 0.000281 0.000565 21 Peugeot 1.167864 0.000397 0.001815 22 Publicis.Groupe 0.766560 0.000260 0.000138 23 Renault 1.179235 0.000401 0.001710 24 Safran 0.817855 0.000278 0.000848 25 Saint.Gobain 1.052387 0.000357 0.000490 26 Sanofi 1.092595 0.000371 0.000161 27 Schneider.Electric 1.025148 0.000348 -0.000516 28 Societe.Generale 1.097510 0.000373 0.000728 29 Solvay 0.946178 0.000321 -0.000478 30 Technip 0.768777 0.000261 -0.000291 31 Total 1.023443 0.000348 -0.000118 32 Unibail.Rodamco 0.945803 0.000321 0.000402 33 Valeo 1.125828 0.000382 0.001261 34 Veolia.Environ. 0.843456 0.000287 0.001561 35 Vinci 0.830486 0.000282 0.001035 36 Vivendi 0.713295 0.000242 -0.000135

# execute this part to modify the css style
from IPython.core.display import HTML
def css_styling():
styles = open("../style/custom3.css").read()
return HTML(styles)
css_styling()